
1.はじめに
1.1 本記事の対象者
- Power AutomateDesktopの標準OCR機能を使って文字を読み取りたい人
1.2 本記事の目的
- Power AutomateDesktopの標準OCR機能で読み取ると方法が分かる。
2.PowerAutomateDesktopのOCR機能の精度比較
2021年2月から無料版Power Automateを使って今まで貯めてきたノウハウを解説していきます。

もしよろしければ、確認してみてください!!
2.1 PowerAutomateのOCRの概要
Power Automate Desktopに以下のようなOCRの機能があります。
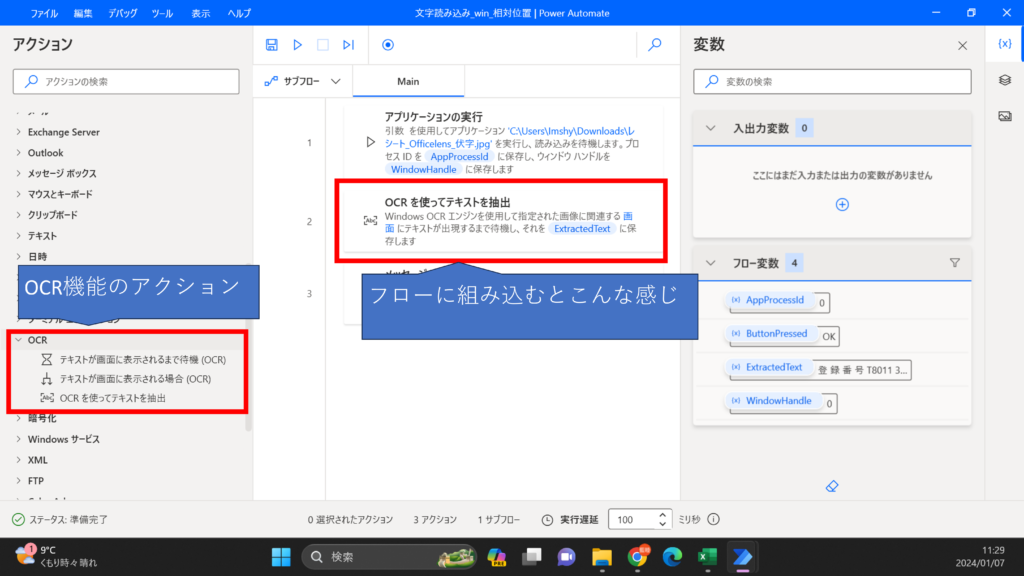
そもそも、OCRとはなんぞやとなるかと思うので、ちょっと調べたことを書きます。
OCRとは、Optical Character Recognition/Readerの略で、日本語で光学的文字認識になります。
自分のイメージでは、手書きの文字や画像に含まれる文字を読み取って、実際の文字データにしてもらう機能と考えています。
最近だと、下のようなイメージで、家計管理アプリでレシートの金額を読み取る機能とかがありますが、その機能をイメージしてもらえればいいかと思います。
そんなOCRの機能が無料版のPower Automate Desktopにあるということで、非常に気になったので試しに使用してみました!
2.2.Power Automate Desktopの標準のOCR機能の取り込みの手順
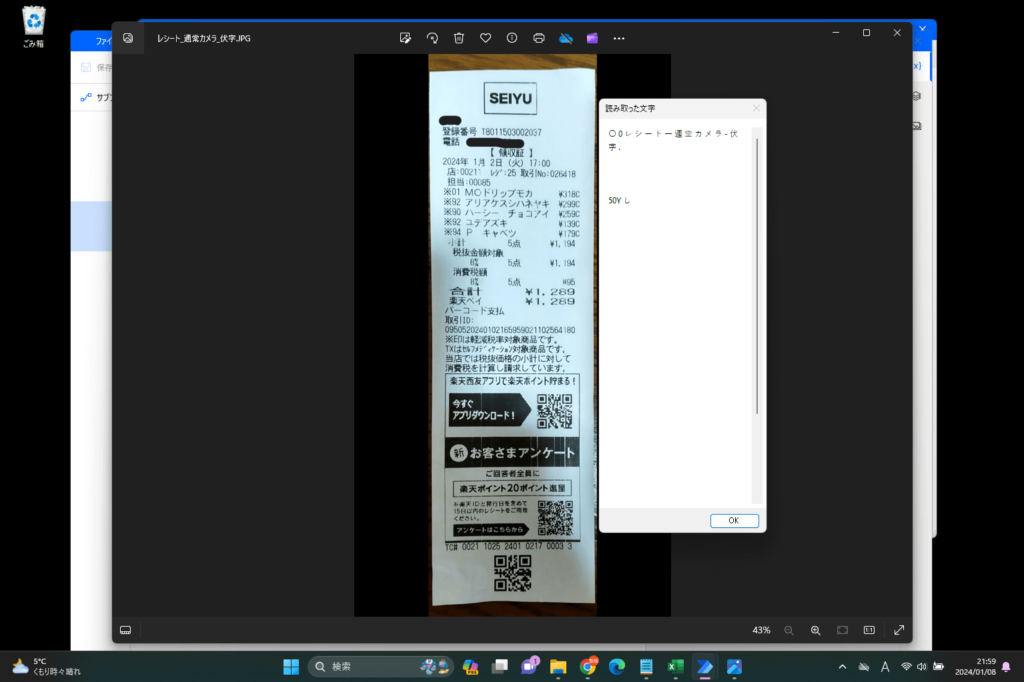
今回取り込む情報は、近所で商品を買ったときに入手したレシートです。(下図がそのレシート)

以下の記事でも書いたのですが、そのままの写真だと全然読み取られなかったです。
ちなみに、そのままの写真を読み取った際の結果が下のものになります。
試行錯誤した結果、元画像をMicrosoftの提供アプリのLensで、「ホワイトボード」用撮影モードを用いることで改善されることに気づきました。
そのため、今回の使用する画像は、内容は同じ以下の画像になります。

それでは、以下にPower Automate DeskTopの標準機能のOCRの読み取り手順を説明していきます。
2.2.1.PowerAutomateDeskTopの新規フロー作成画面への遷移
まずは当たり前ですが、新規フローを作成するための画面に遷移します。
2.2.2.読み取る対象の画像を立ち上げるアクションを設定
次に、OCRで読み取る対象である画像ファイルを起動するためのアクションを追加します。
該当のアクションは、「システム」-「アプリケーションの実行」を選択します。
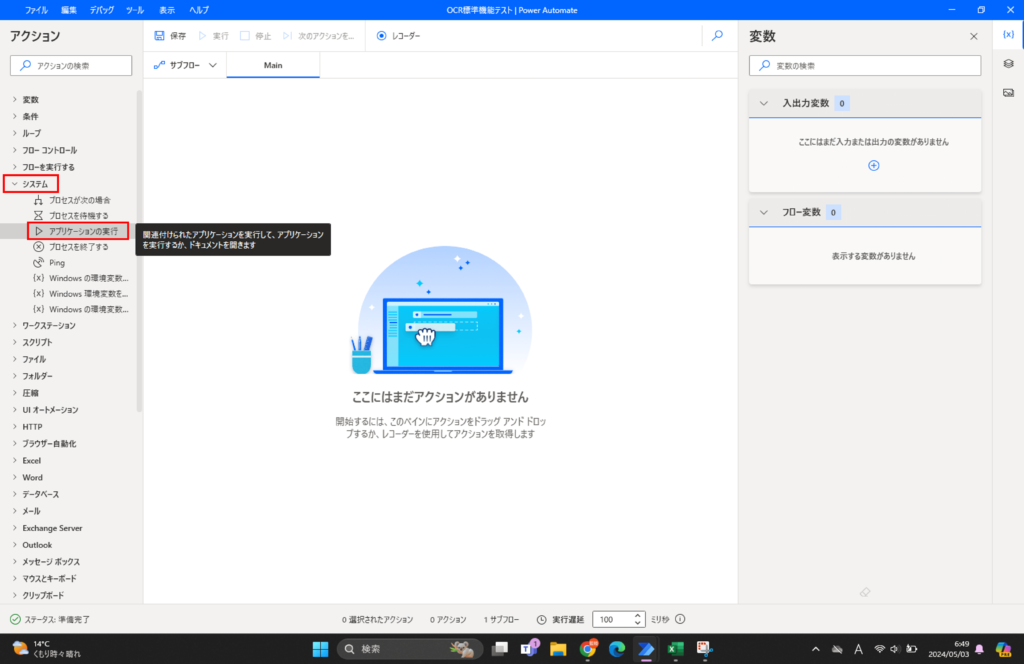
「アプリケーションの実行」を選択した後の設定項目では、以下2つの項目を設定します。
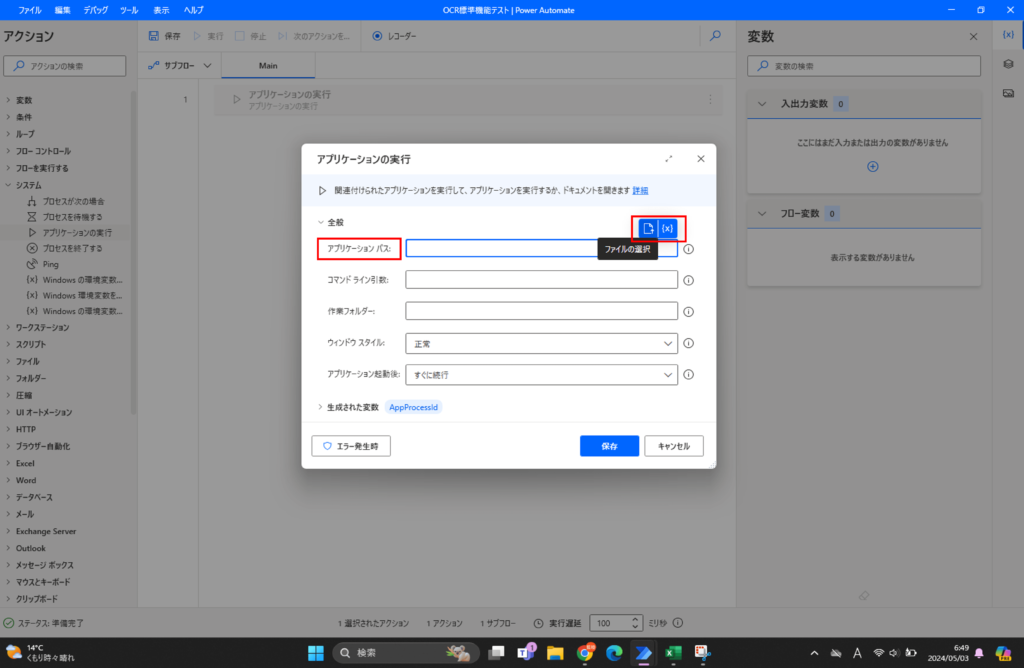
- アプリケーションパス:対象の画像ファイルのパスを選択
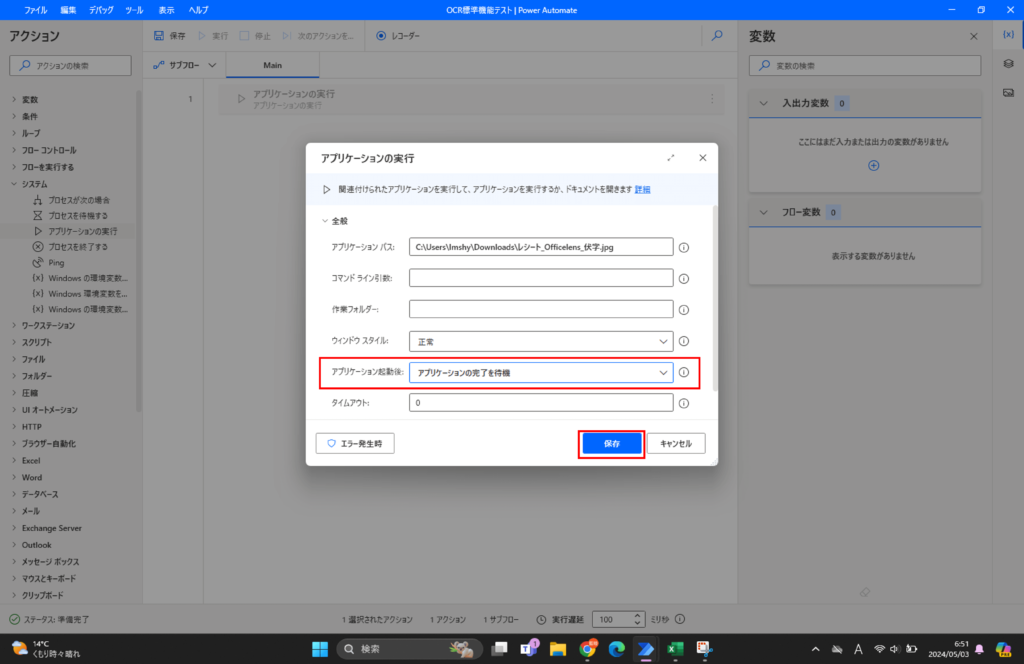
- アプリケーション起動後:「アプリケーションの完了を待機」
No1は単純に画像ファイルのあるパスを選択して、設定します。
No2は、取り込み対象の画像ファイルが立ち上がったのを確認したのちに、次のアクションに移るため、「アプリケーションの実行」を設定します。
2.2.3.OCR機能で読み取るための設定
続いて、OCR機能の読み取り設定のための手順です。
アクションに存在する「OCR」では、画像読み取りに相対位置を設定するのが面倒くさいため、上部に存在する「レコーダー」から設定する方法にします。
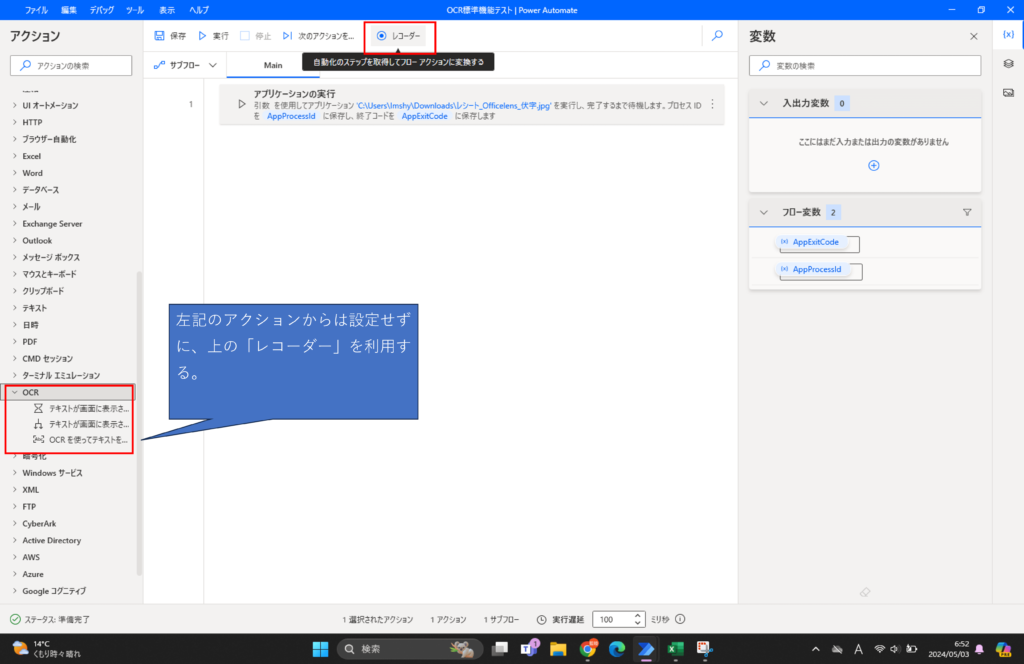
「レコーダー」を設定した後に、読み取りたい画像を全画面にした上で、読み取り設定をします。
「読み取りたい画像を全画面にした上で」というのは、画像ファイルを開いた時の大きさによって、相対位置がずれて読み取れないようなので、全画面にするようにした方いいと思います。
設定には、ウィンドウ「レコーダー」の右上に存在する「︙」を押下します。
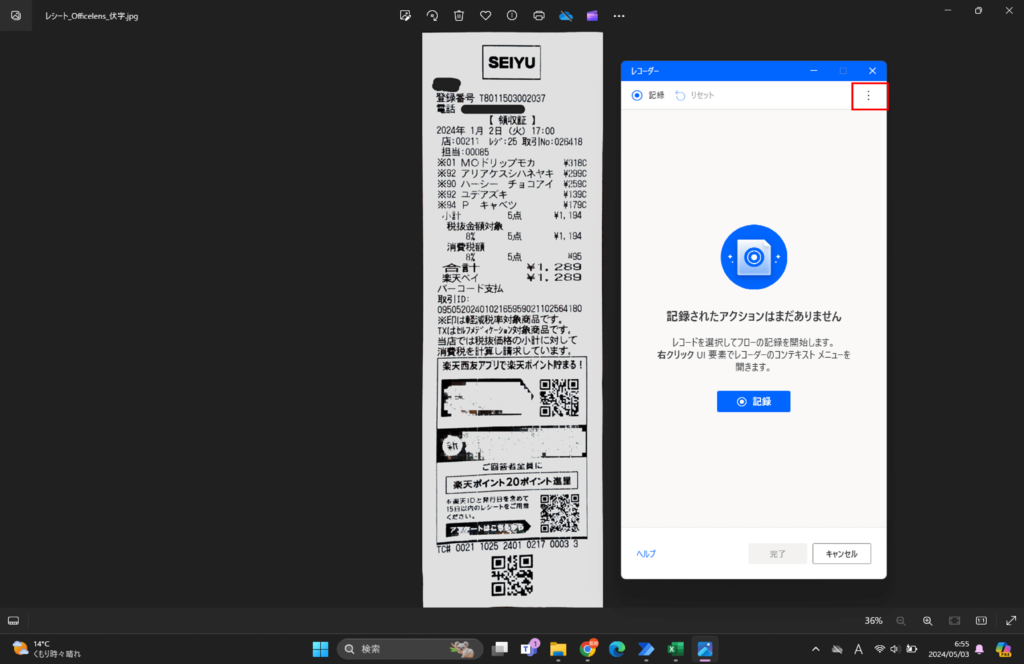
すると、「画像記録」という項目が表示されるため、項目を画像の通りオンにして「記録」を押下します。
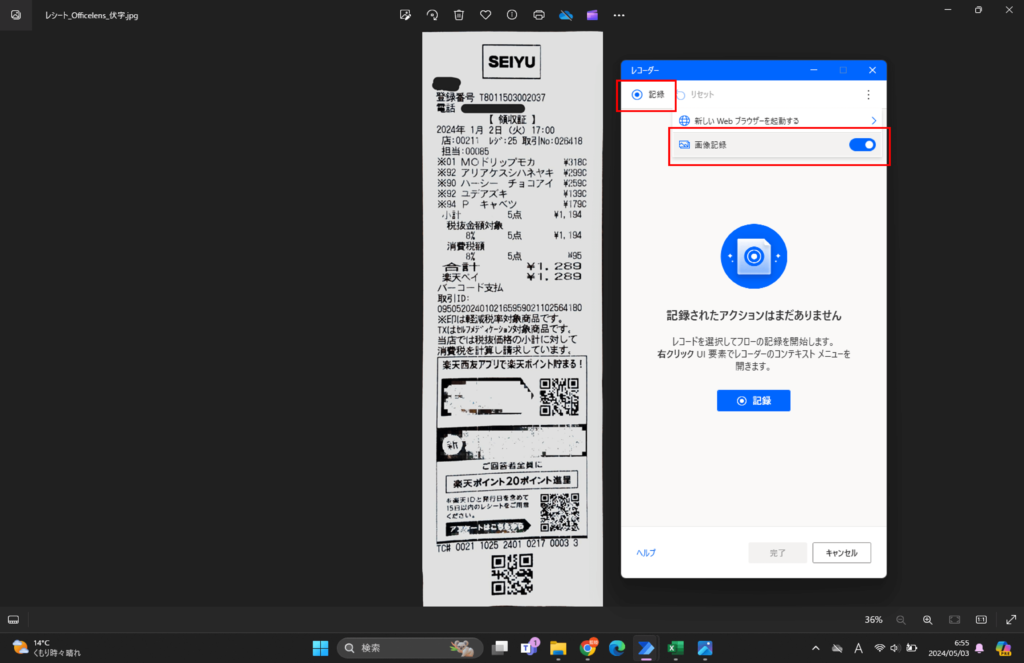
「記録」が「一時停止」に変更されていることを確認します。
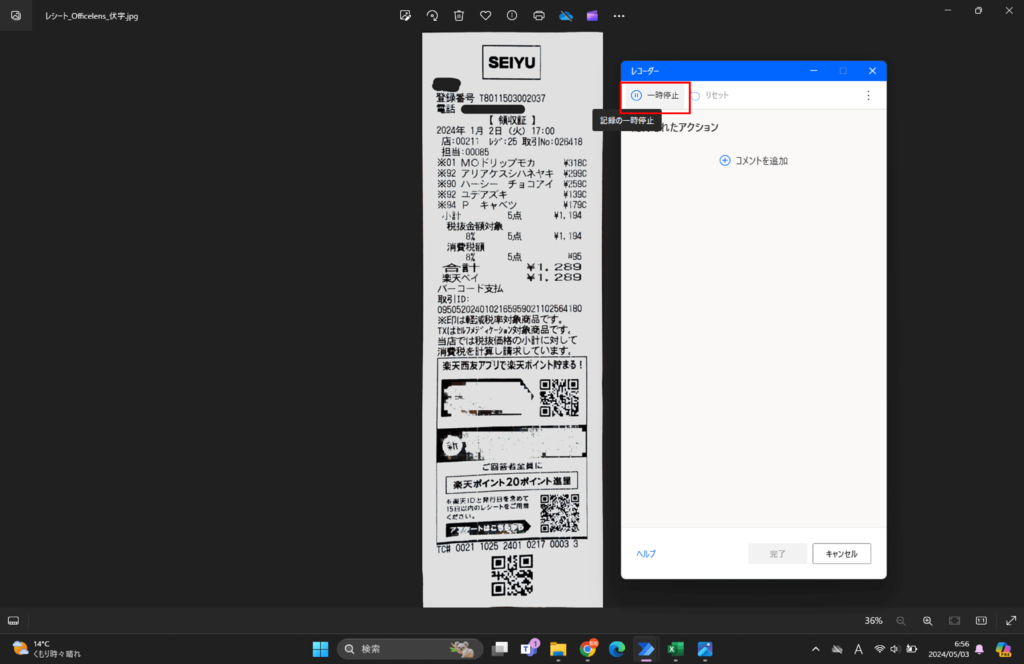
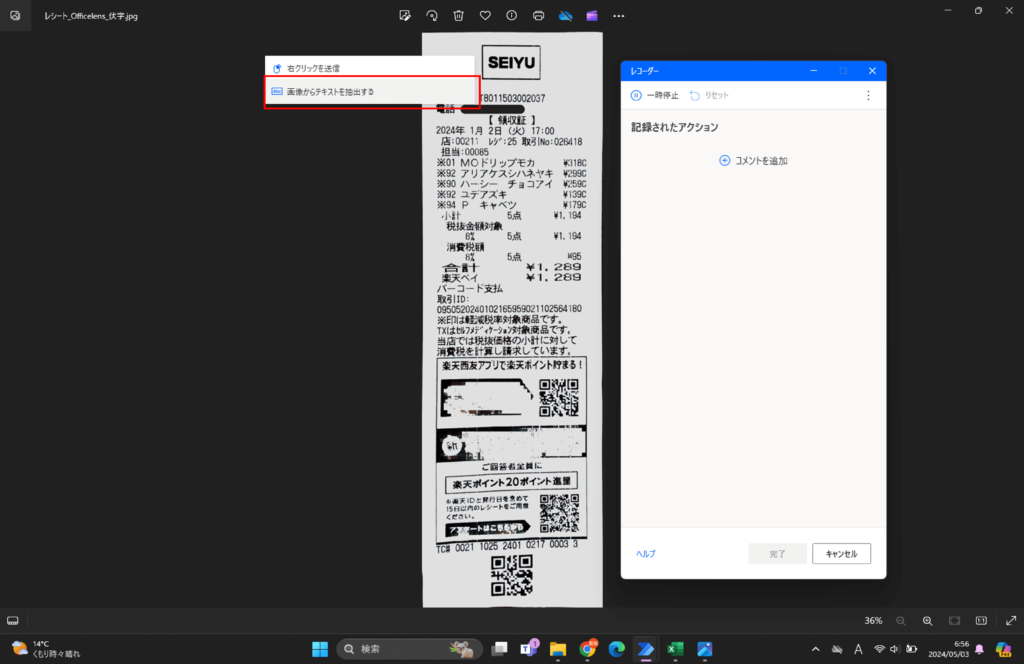
続いて、読み取りたい画像の上で、右クリックをします。
右クリックすると下のように、「画像からテキストを抽出する」が表示されるので、押下します。
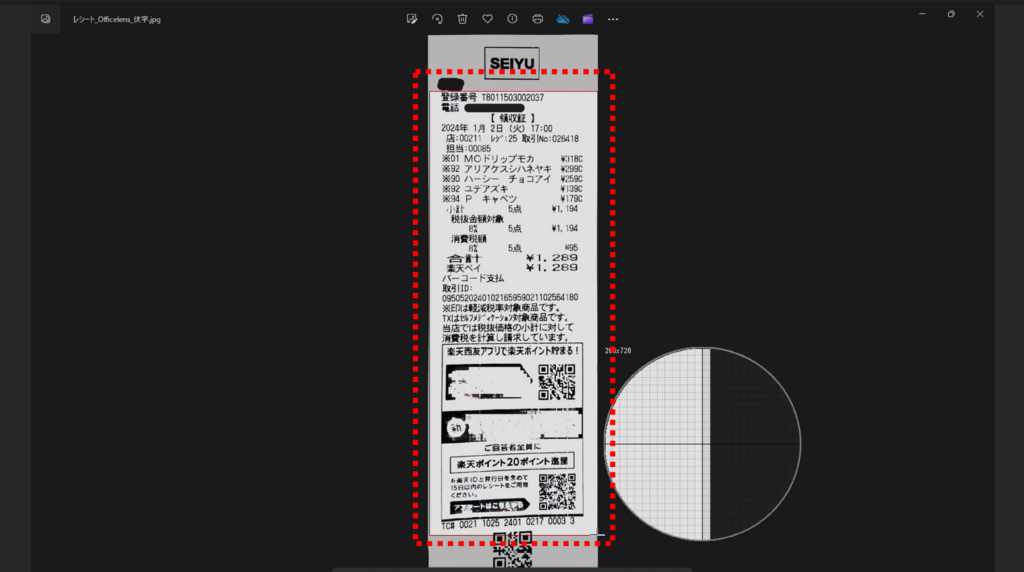
上に「1/2:テキスト領域を定義する」という表示がされていることを確認します。

「テキスト領域」とは、読み取りたい箇所の領域のことです。
今回は、「SEIYU」の文字より下の文字を読み取ることにするため、以下の範囲を設定します。
次に「2/2:アンカー領域を定義する」という表示がされていることを確認します。
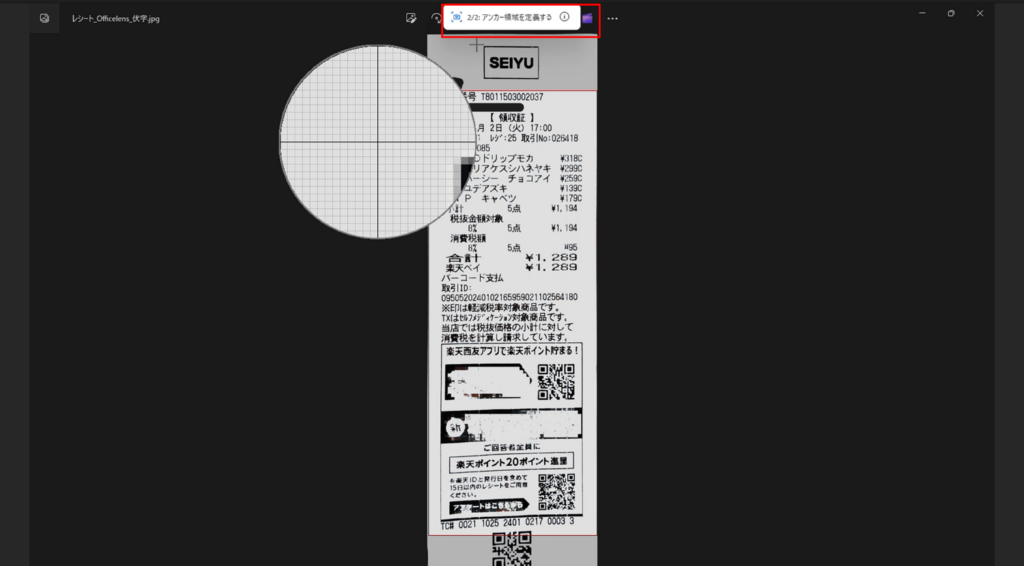
「アンカー領域」とは「テキスト領域」の目印となる画像のことです。
今回でいうと、「SEIYU」という文字画像の下を「テキスト領域」にしたいため、「SEIYU」という文字を設定します。

「SEIYU」という文字を設定すると、ウィンドウ「SEIYU」にOCR機能で読み取った文字が表示されます。
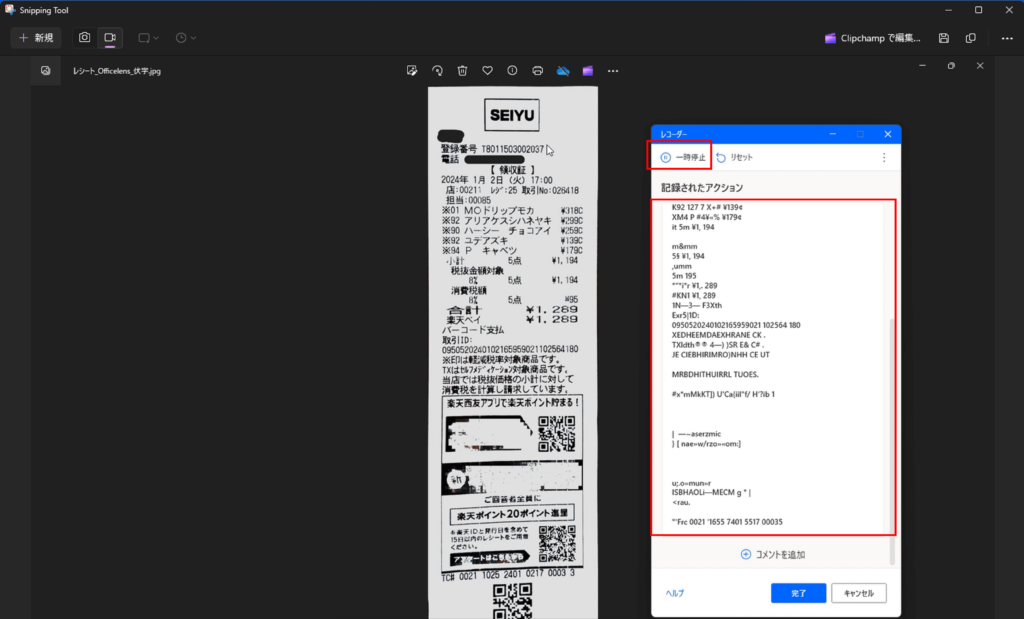
デフォルトが英語を読み取るようになっているため、上の画像では文字化けしているように見えますが、気にせずに「一時停止」を押下します。
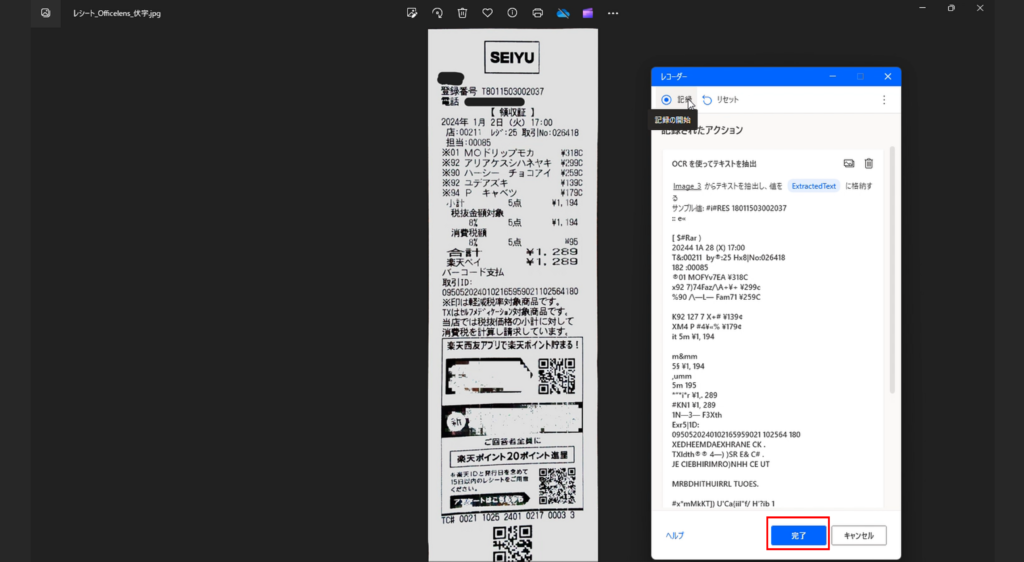
「一時停止」が「記録」に変更になったのを確認して、「完了」を押下します。
なぜだか、「コメント」というアクションが自動で挿入されていたため、アクション「コメント」を選択します。
そして、右クリックを押したのちに「削除」を押下します。
「OCRを使ってテキストを抽出」をダブルクリックして、設定画面を表示させます。
今回の注目すべき設定値は、以下になります。
- OCRエンジンの種類:Windows OCRエンジン
- OCRソース:フォアグラウンド ウィンドウ
- 検索モード:画像に対するサブ領域の相対値
- 画像:アンカー領域で設定した画像←前の設定で既に設定済
- Windows OCRの言語:日本語←デフォルトは英語になっている
- 生成された変数:OCR機能で読み取った値を格納する変数←好きに変えてください。
下の画像がそれぞれの値をセットした状況です。
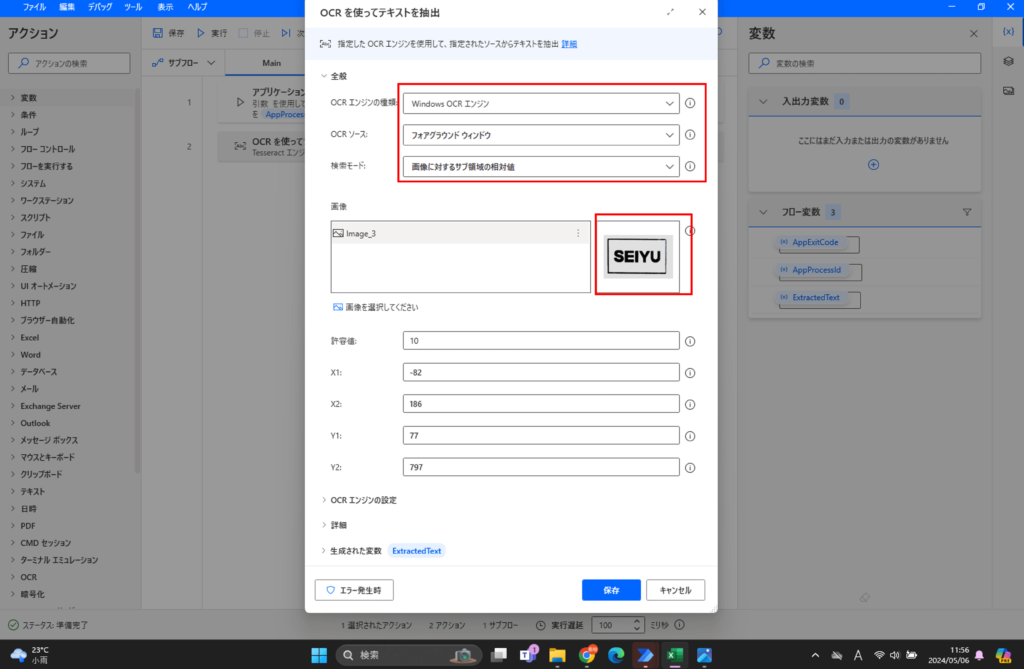
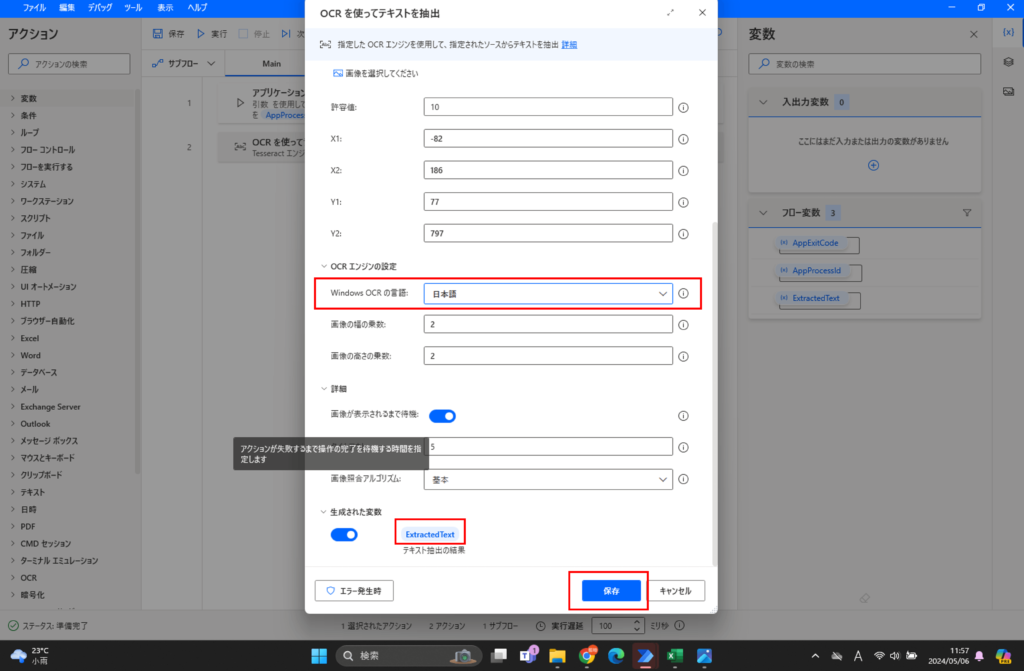
設定項目を反映するために、最後に「保存」を押下します。
2.2.4.読み取った値を表示する
OCR機能で読み取った値をメッセージボックスで表示するようにします。
これは結果確認のためにやっているため、通常の業務で使用する場合は、Excelに転記など処理を入れることになると思います。
アクションの中から「メッセージボックス」-「メッセージを表示」をフローに追加します。
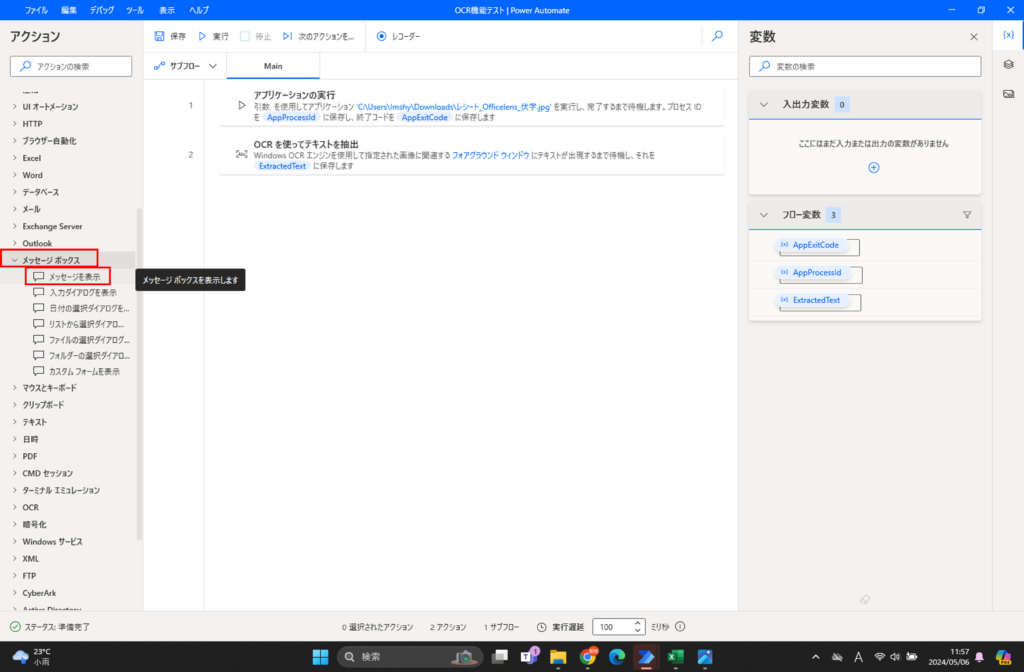
設定を変更する画面では、以下の項目を設定します。
- メッセージボックスのタイトル:テスト←今回はなんとなく入れました。
- 表示するメッセージ:前項の「生成された変数」の値を選択して設定
No2の設定は、以下のように「変数の選択」を押下します。
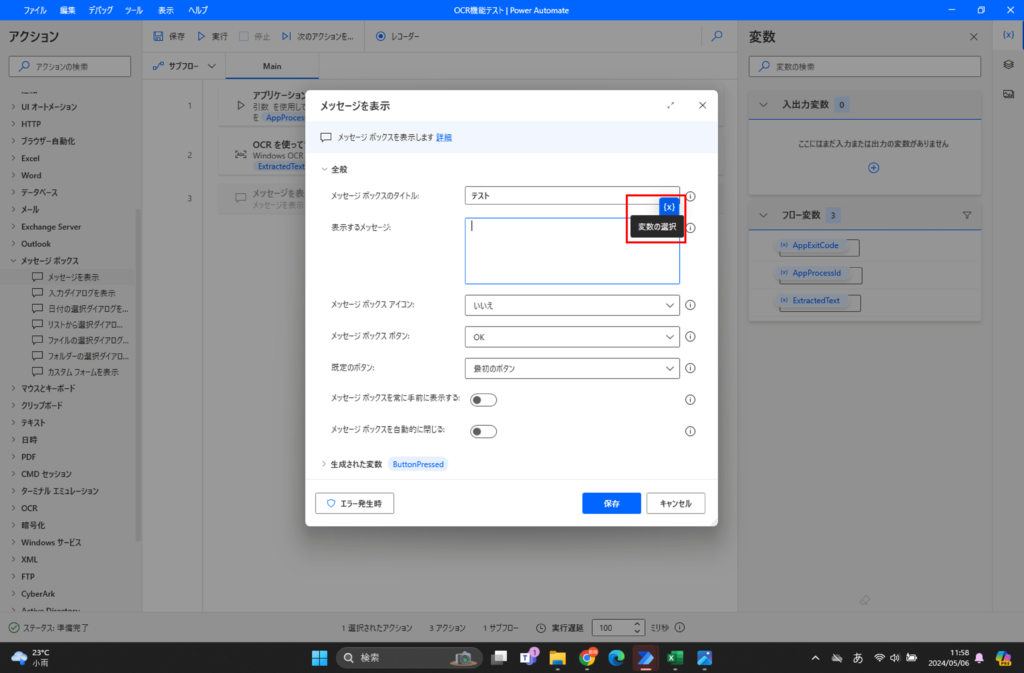
その次に、「生成された変数」である「ExtractedText」を選択します。
他の項目は変更しないため、「保存」を押下します。
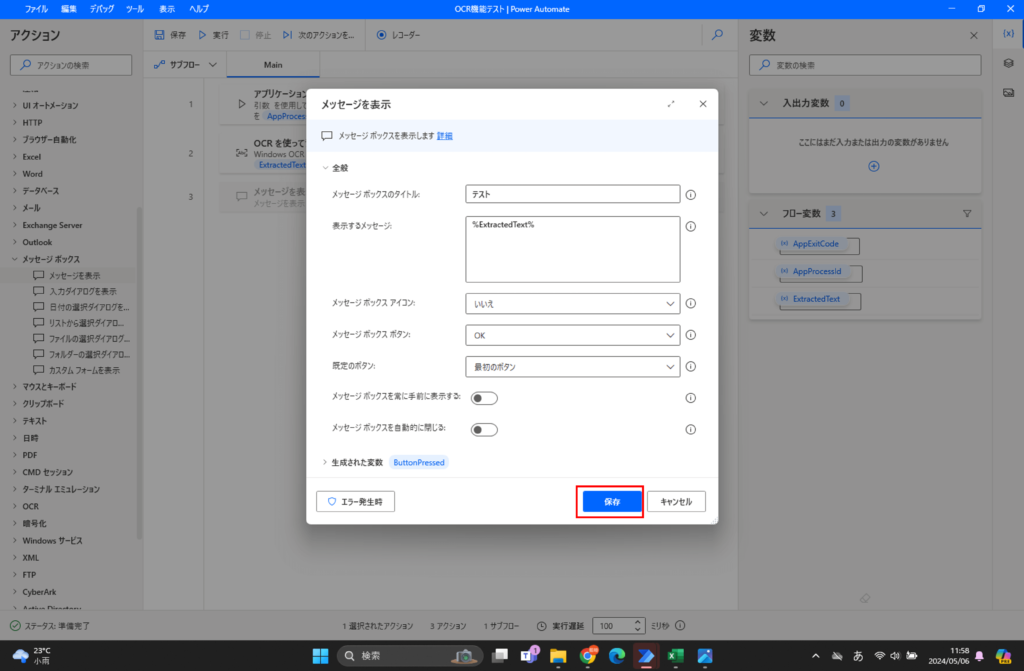
以下のように設定がされれば、完成です。
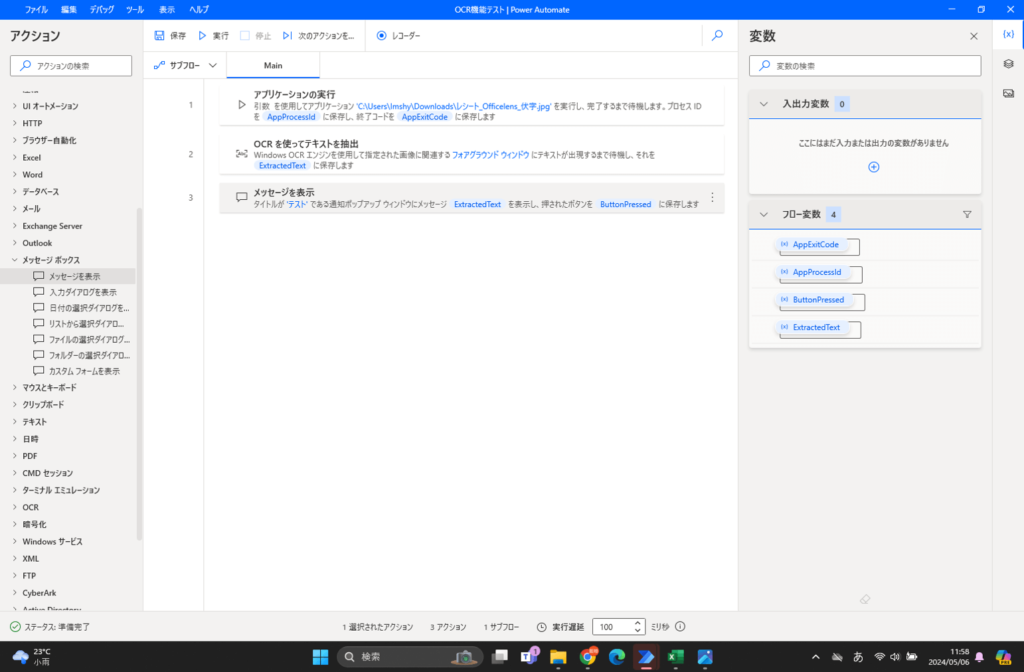
2.3.実行結果
完成したフローを実行するため、上部の「実行」を押下します。
そうすると、画像から読み取れた文字が以下のように表示されます。
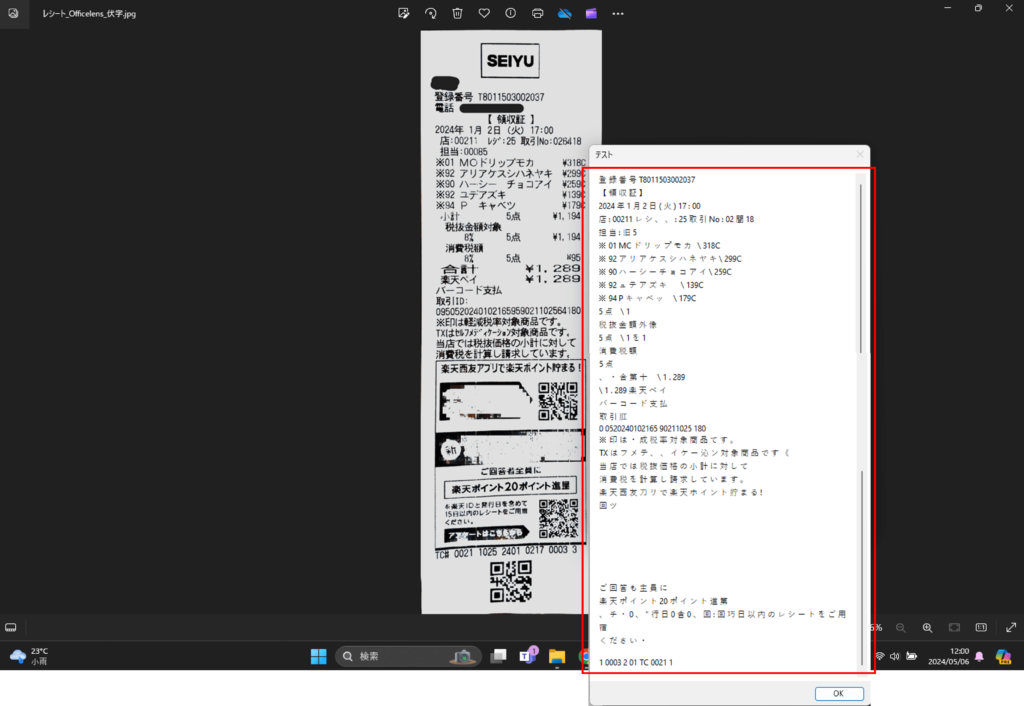
100%読み取れているわけではないですし、改行等の処理が必要かもしれませんが、ある程度読み取れていることが以下の画像で分かります。
3.まとめ
まとめに入ります。
業務効率を上げるために提供されているMicrosoft365のツール群で、今回はPowerAutomateのアクション「OCR機能」精度向上について説明しました。
使い方としては、帳票の画像から金額を取得したり、単語帳を自分で写真撮影して自分用の単語帳の元データにしてもらえたりするのかなと思いました。
最後まで読んでいただきありがとうございます


コメント